继KaggleGameArena的淘汰赛后,国际象棋积分赛成果出炉!OpenAIo3以人类等效Elo1685分傲视群雄,而Grok4和Gemini2.5Pro紧随其后。DeepSeekR1和GPT-4.1、ClaudeSonnet-4、ClaudeOpus-4并列第五。
别再拿淘汰赛说事了!
这次是真刀真枪的「积分赛」,Elo榜单才是硬实力。
40轮血战,国际象棋AI仅文本输入结果出炉了。
仅使用文本输入、无工具、无验证器,各大AI模型进行对决。
每组配对进行超过40场比赛,构建了类似围棋等运动项目的Elo排名。
OpenAIo3独占鳌头,Grok、Gemini位列榜眼。
第一名:o3,估计人类Elo为1685分,而人类大师水平为2200分!
第二名:Grok4,估计人类Elo为1395分,表现不错。
第三名:Gemini2.5Pro,估计人类Elo为1343分,稍逊一筹。
另外,值得一提的是DeepSeek-R1-0528和GPT-4.1、ClaudeSonnet-4、ClaudeOpus-4并列第五。
GameArena的首次AI国际象棋比赛,o3最后夺冠,这次这次证明实力。
之前,Kaggle举办了首届AI国际象棋表演赛,展示了o3、Grok4、Gemini2.5、DeepSeekR1等通用模型在国际象棋方面的表现。
这些模型进步明显,大家从中获得了不少乐趣,比如发现大语言模型特别喜欢西西里防御开局。
但四局三胜的淘汰赛偶然性太大,并不能严格衡量模型的真实水平。
因此,今天谷歌旗下的Kaggle正式发布了GameArena平台上的国际象棋文本排行榜。
排行榜链接:https://www.kaggle.com/benchmarks/kaggle/chess-text/leaderboard
国际象棋文本排行榜是一个严格的AI基准测试平台。前沿大语言模型在此竞技,全面考验它们的战略推理、规划、适应和协作能力。
平台通过透明的测试设计、丰富的游戏数据和不断更新的多游戏排行榜,为评估AI的真实认知能力提供了动态且可复现的标准。
该排行榜基于所有参赛模型之间的循环赛结果,每对模型进行20场白棋和20场黑棋的对决,总共40场比赛。
这次还扩大了参赛模型范围,不仅包括上周表演赛的8个模型,还增加了更多模型,以提供更全面、更可靠的评估结果。
GameArena的Elo分数采用标准的Bradley-Terry算法,基于模型之间的对战结果计算。
为了估算这些模型的人类等效Elo评分,它们与L0到L3不同等级的国际象棋Stockfish引擎对弈。
通过线性插值法,根据Stockfish各等级对应的人类Elo评分,计算出大模型的人类等效Elo分。具体来说:L0对应1320分,L1对应1468分,L2对应1608分,L3对应1742分。
需要注意的是,这些模型距离顶级人类棋手仍有较大差距:
人类「大师」级棋手的评分为2200或更高,
「特级大师」为2500或更高,
而最强版本的Stockfish引擎估计的人类Elo评分高达3644。
Stockfish是一款免费且开源的国际象棋引擎。
自2020年以来,Stockfish赢得了顶级国际象棋引擎锦标赛(TCEC)和Chess.com计算机国际象棋锦标赛(CCC)的所有主要赛事,并且截至2025年8月,它是世界上最强的CPU国际象棋引擎,估计的Elo等级为3644,
置信区间则通过500次重采样比赛结果,并分别计算GameArenaElo和人类Elo分得出。
除了Elo分数,这次还增加了「平均每回合Token数」和「平均每回合成本」等指标,以反映模型在性能和效率之间的权衡。
自然,这个排行榜也有一些限制和缺陷:
(1)仅限于国际象棋:没有任何单一游戏可以捕捉智能的全部范围。Kaggle将努力通过随着时间的推移引入更多游戏来缓解这一问题。
(2)超时限制:施加严格的每步棋时间限制可能会惩罚那些需要更长时间才能得出结论、进行更深入思考的模型,从而偏向于那些速度更快但可能更肤浅的策略。
(3)抽样随机性:使用了模型提供商设置的默认抽样参数。这些参数可能具有非确定性。
你可以在Kaggle的YouTube播放列表中观看带解说的表演赛,但排行榜上提供了更多的对局回放。只需点击模型旁边的回放图标,选择想要观看的对局即可。
此外,这次还发布了一个包含可移植棋谱(PGN)和模型公开推理过程的数据集:国际象棋文本输入基准测试「ChessTextGameplay」。
数据集链接:https://www.kaggle.com/datasets/kaggle/chess-text-gameplay
国际象棋文本输入基准测试旨在评估和比较当今通用语言模型的战略推理能力。
这是Kaggle公开基准测试平台GameArena的首个项目,该平台让AI模型在复杂的战略游戏中竞技,将严谨的科学方法与观赏性的竞赛体验相结合。
为什么这很重要?Kaggle介绍了三大理由:
超越数据污染问题:静态测试无法区分模型的真实推理能力和记忆答案的能力。而在国际象棋文本输入测试中,每一步决策都源自模型的内部逻辑,确保评估的是真实的思考过程。
高压环境下的表现:模型必须随机应变、从错误中恢复,并抓住不断变化的机会,如同人类国际象棋大师一样应对复杂局面。
通用人工智能(AGI)的洞察:在此领域取得成功,意味着模型在多步骤战略问题解决方面达到了重要的里程碑,为通用人工智能的发展提供了有价值的参考。
超越数据污染,这才是AI的「高考」!
每一步棋,都考验着大模型真·战略推理、规划和应变能力。
他们也指出了该数据集的一些局限性,包括:
推理:推理输出是模型思考过程的生成性摘要。它不是内部计算的字面追踪,因为模型通常会隐藏其内部思考过程。
测试框架:模型的性能与用于此基准测试的特定测试框架(更多细节)内在相关。
时间快照:该数据集代表了这些特定模型版本在收集时点的性能。
数据结构「PGNs_with_reasoning」(包含推理的PGN)数据集包含表示大型语言模型所下国际象棋游戏的便携式游戏记谱法(PGN)文件。每个PGN文件由国际象棋记谱和大型语言模型在每一
Kaggle计划定期将新模型加入国际象棋文本排行榜及其他GameArena排行榜,以跟踪AI模型在战略规划、推理和其他认知能力方面的进步。
未来,GameArena将推出更多游戏的排行榜,为AI模型的能力评估提供更全面的基准。
今天的国际象棋文本排行榜只是第一步。
参考资料:
https://x.com/kaggle/status/1958546786081030206
最新发现
相关资讯
刚刚,大模型棋王诞生,40轮血战,OpenAI o3豪夺第一,人类大师地位不保?
GameArena首次积分赛排行榜
2025-09-04 09:12:10

苹果新AI模型长视频理解夺冠,小至1B版本也领先对手
科技媒体9to5Mac今天发布博文,报道称苹果研究团队开源SlowFast-LLaVA-15长视频多模态大语言模型,在1B、3B、7B参数规模下,均刷新LongVideoBench、M
2025-09-03 09:08:23
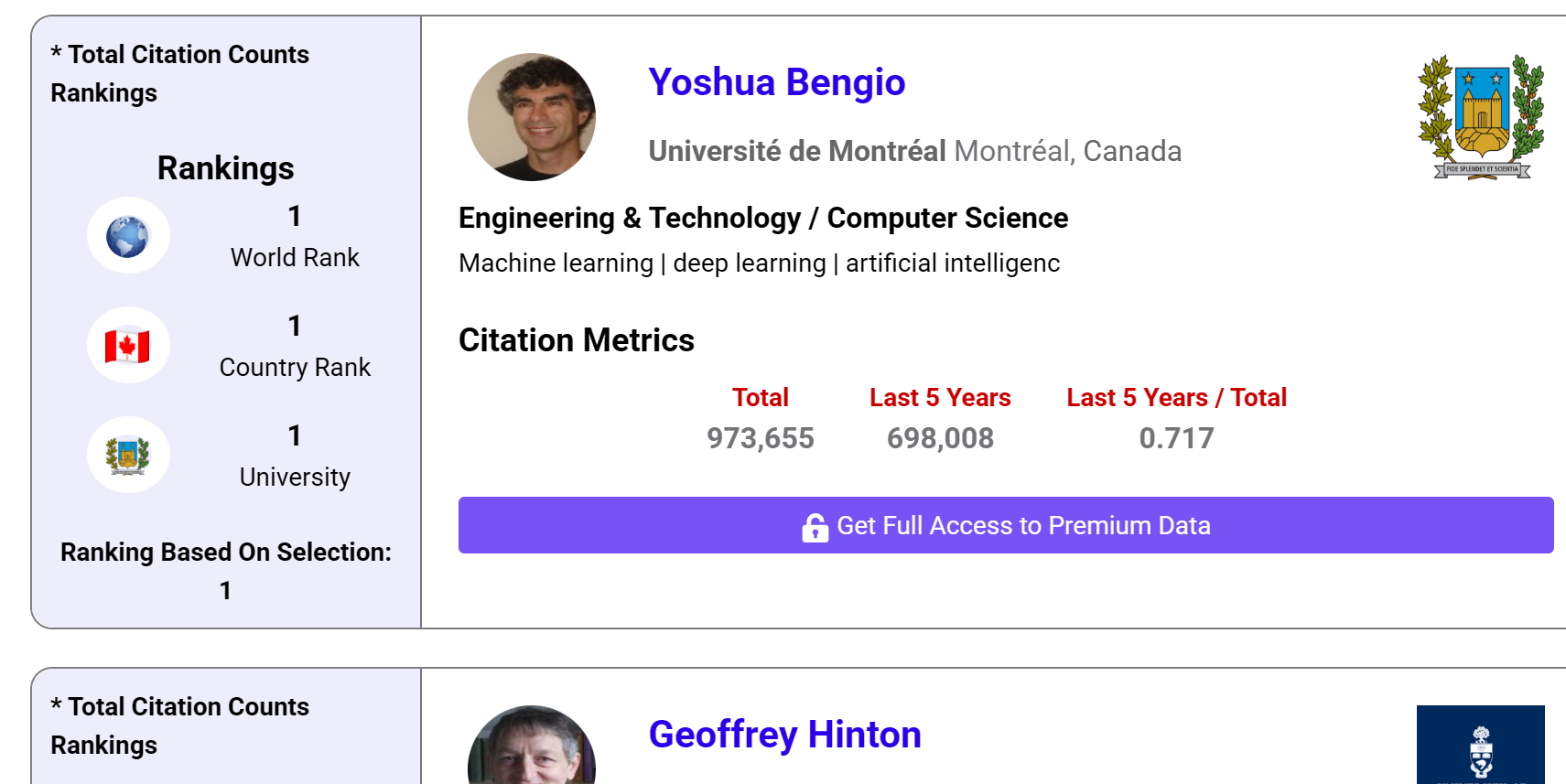
科学界论文高引第一人易主!AI站上历史巅峰
图灵奖得主YoshuaBengio,论文总引95万+魔镜魔镜,谁是有史以来被引用次数最多的科学家?答案:深度学习三巨头之一、图灵奖得主YoshuaBengio。
2025-09-03 09:08:20

钉钉发布8.0版本:推出下一代AI办公应用形态钉钉ONE
8月25日消息,今日,钉钉发布80版本,推出了下一代AI办公应用形态:钉钉ONE。钉钉ONE被设计为人与AI通过自然语言对话的统一入口,致力于打造全球首个以Agent驱动的工作信息流,让工作处
2025-09-03 09:08:17

马斯克成立新公司「巨硬」:用AI把微软产品重做一遍
论搞事情,还得是你马斯克。这不,为了硬刚微软,老马直接成立了一家新公司——巨硬(Macrohard)。就冲这个名字哈,那可真叫一个贴脸开大。不论是中文还是英文角
2025-09-03 09:08:14

AI演进:推动5G与Wi-Fi连接方式的变革
要点:通过高通X855G调制解调器及射频和高通FastConnect7900移动连接系统支持的AI连接技术,蜂窝网络与Wi-Fi网络之间可实现无缝切换,从而提升游戏和视频通话等应用的实时性能表现。
2025-09-03 09:08:10
今日热榜
“保守1000亿”,这个赛道正在批量制造90后富豪
2025-07-30 09:13:12WAIC UP!之夜:一场关于AI与人类未来的星空思辨
2025-07-31 09:08:13消息称微软与OpenAI正进行深入谈判:确保AGI时代技术合作
2025-07-31 09:08:16赋能医疗健康等领域北京亦庄发布全域人工智能之城建设首批成果
2025-02-06 09:55:372024年中国人工智能之自然语言处理(NLP)技术洞察
2025-03-28 09:29:09广州互联网法院参加人工智能发展与侵权法国际论坛
2025-05-02 21:54:13成都人工智能行业薪资第三2024年招聘月薪9813元
2025-05-14 17:37:24从“炼丹”到“开店”:大模型应用商店,能否解开国产AI的“商业化焦虑”?
2025-07-29 09:11:26第六届国际青年人工智能大赛总决赛在雄安举办
2024-12-20 13:54:23当蔡国强“指导”AI创作:灵魂扫描,灵性交集
2025-01-08 15:35:58热门推荐









